Continuous Profiling
2021/06/10
Continuous Profiling (CP) adalah proses mengumpulkan data performa aplikasi yang berjalan di production dan membuat data tersebut dapat dianalisa oleh si pembuat kode.
Pembuat kode bisa menginsvetigasi performa bottlenecks di production dan mengidentifikasi masalah. Kejadian nyata, beberapa kali kita melihat ada aplikasi yang selalu direstart karena kehabisan memory dan CPU. Tapi sulit untuk mencari fungsi apa yang menyebabkan masalah itu terjadi.
Kenapa performa tools penting
Ada 3 kategori besar yang menyangkut masalah kinerja dari software, yaitu.
Known Knowns
Kita tau akan terjadi masalah dan tau penyebabnya apa
Misal kita sudah tau kalau membaca data dari memory utama akan lebih cepat daripada membaca dar hardisk. Ini menjadi mental model yang kita yakini dapat diandalkan. jadi kita sudah bisa merencanakan lebih dulu dalam memilih jenis data yang akan digunakan.
Known Unknowns
Kita tau terjadi masalah, tapi tidak tau apa penyebabnya.
Kita tau ada penggunaan memory dalam kode yang kita tulis dan jika memory yang digunakan lebih dari yang tersedia diserver production, maka akan terjadi masalah, tapi kita tidak tahu akan seberapa besar masalahnya.
Karena kita tau akan jadi masalah maka kita bisa mencegahnya dengan merencanakannya.
Unknown Unknowns
Kita gak tau ini akan menjadi masalah, dan gak tau penyebabnya.
Ini adalah inti dari masalah yang sebenarnya. Kita gak tau kalau ini masalah sampai kita tau kalau aplikasi kita rusak. Baru kita tau kalau ada kode yang cacat, misalnya menghabiskan jumlah memory yang tersedia.
Maka dari itu kita perlu cara untuk mengukur kinerja dari aplikasi kita dengan cara melakukan performance test dan profiling aplikasi kita.
Development bukan production
Tujuan dari dari performace testing adalah untuk menghilangkan bottleneck di production. Kita menggunakan test ini untuk membuat production menjadi lebih cepat.
Kita biasanya melakukan performance test dengan mudah menggunakan desktop tools, membuat seolah-olah ditest seperti production, tapikan tidak bisa seperti itu. Kenapa?
Ya masalahnya, hardware yang digunakan specnya beda dengan di production dan mungkin software yang berjalan juga beda misalnya, beda versi kernel atau versi runtime dari bahasa pemrogramannya.
Jadi, kalau kita tidak bisa menggunakan environment yang sama dengan production, maka gak ada jaminan kalo kita bisa mengoptimalkan dengan cara yang sama kaya di production.
Profiling vs Monitoring
Kita perlu memahami bagaimana sistem berkerja dalam environment production yang realistis dan load yang nyata. Dari mana saja kita bisa tau informasi mengenai sistem diproduction untuk memahami kerjanya? Bisa dari metrics, logging dan profiling.
Metrics
Metrics sangat berguna. dia dapat mempersempit masalah dengan sangat cepat dan memberitahu apakah sedang ada masalah pada sistem kita. Namun metrics tidak bisa memberitahu kita code mana yang harus kita perbaiki dan kadang metric juga menyebabkan banyak anomali. kita tau ada masalah tapi kita harus menebak-nebak dulu masalahnya dibagian yang mana.
Dengan metrics orang cenderung ingin mengumpulkan data sebanyak mungkin,
- Are you the metric that caused this problem?
- Are you have the metric that caused this problem?
- Are you the metric that caused this problem?
Logging
Logging adalah cara lain untuk mengambil informasi dari production sistem. Biasanya kita melakukan log pada aplikasi secara manual melalui code yang kita buat. Yang sering kali informasinya sangat berguna dan sangat detail tentang sistem. Tapi, itu adalah perkerjaan manual, dan makin banyak yang kita log akan mempengaruhi performa aplikasi juga.
Profiling
Profiling menghubungkan beberapa penggunaan sumber daya dari sistem ke komponen dalam software kita.
Jadi kita bisa melihat dan menjawab pertanyaan seperti ini,
- What methods are using up CPU time?
- What lines of code are allocating objects?
Profiling menjadi sesuatu yang bagus jika ada, karena dia berkerja secara otomatis artinya kita hanya perlu menyematkan beberapa baris kode untuk menmasang profiler dan kita tidak perlu menyesuaikan kode yang sudah kita buat.
Continuous Profiling
Ada gak sih cara lebih baiknya?
Cara yang lebih baik tentunya tidak hanya melihat metrik, tapi kita juga ingin mendapat sesuatu yang bisa ditindaklanjuti. Kita mau sesuatu yang bisa mengatakan “Dimana code yang perlu kita perbaiki?”.
Continous Profiling adalah cara kita melakukan profiling di environment production.
Dengan memasang profiling kita dapat melihat penggunaan sumberdaya dari waktu kewaktu.
Kita bisa melihat kode atau method apa yang menghabiskan resource paling banyak. Setelah itu bisa kita perbaiki lalu kita lihat lagi, apakah setelah diperbaiki menjadi lebih baik?
Pada dashboard profiling kita akan melihat CPU time dan wall clock time. Dua istilah ini yang nantinya akan sering kita lihat.
Untuk mengerti apa itu CPU time dan apa itu wall clock time, analoginya seperti ini.
Bayangkan kita sedang pergi ke coffee shop pada saat makan siang. Disana kita akan melihat antrian panjang. Jadi CPU time adalah waktu berapa lama barista membuat kopi dan wall clock time adalah proses menunggu pembuatan kopi untuk orang lain yang antri sebelum kita.
Visual yang akan kita lihat biasanya berbentuk flamegraphs. Flamegraphs berbentuk kotak kotak, setiap kotak mewakili sebuah method.
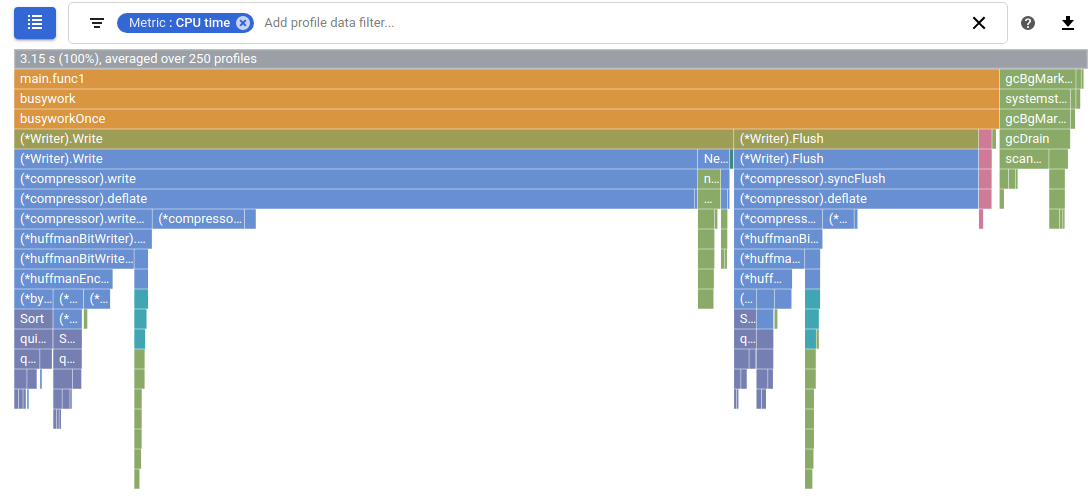 ]
]
Bagaimana cara kita impelmentasi Continous Profiling?
Salah satu paper bagus yang bisa dibaca Google-Wide Profiling.
Kalo gak mau repot google jual jasanya kok namanya Cloud Profiler
Atau bisa juga pake yang opensource misalnya pyroscope
Kesimpulan
Mungkin kok melakukan profile di production dengan low overhead. Untuk mengatasi beberapa masalah yang praktikal, ya kita harus membuat profile setiap saat, ini membuat kita jauh lebih mudah. gak nebak nebak lagi.
Referensi: